Minden LLM MI, de nem minden MI LLM


A homo sapiens, avagy köznyelvien az ember, kétségkívül a valaha élt legsikeresebb faj a Földön. Röpke 500 ezer éves jelenlétünk kitörölhetetlen nyomot hagyott a bolygónkon; civilizációnk maradványai még utánunk is sok millió évig őrizni fogják emlékünket.

Az AI (Artifical Intelligence, azaz MI – mesterséges intelligencia) fejlődési történetében az LLM-ek (Large Language Model – nagy nyelvi modell) hasonló szerepet töltenek be, mint mi magunk a földi élővilág történetében. Áttörték az üvegplafont: néhány év leforgása alatt emberek milliárdjainak életében jelentek meg, és jelenleg is zajlanak az általuk okozott drasztikus, az élet számos területét érintő változások, amelyek következményei egyelőre beláthatatlanok. Az LLM-ek azonban csak egy egészen apró szeletét teszik ki az MI kiterjedt és folyamatosan burjánzó családfájának.
A kezdetektől a ChatGPT-ig
Az MI fogalma nehezen definiálható. Egyes vélemények szerint pedig még nem is létezik, mivel a jelenlegi algoritmusok nem rendelkeznek valódi intelligenciával, és nem képesek az önreflexióra. Ebben a cikkben az MI-t mint ernyőfogalmat használjuk: minden olyan módszert ide sorolunk, amely valamilyen módon az emberi – vagy akár az állati – intelligenciát próbálja mesterségesen utánozni.
Az MI-családfa gyökerei meglepően régre, egészen a 18. századig nyúlnak vissza, az érdemi fejlődés azonban csak az 1950-es évek statisztikai módszereinek elterjedésével vette kezdetét. Ezek nyitották meg az utat a gépi tanuláshoz, amely a ma alkalmazott legtöbb MI-rendszer működésének gerincét adja. A gépi tanulás lényege, hogy nem előre megírt szabályok mentén működik, hanem adatalapon, bemenet-kimenet példákon keresztül „tanulja meg” az összefüggéseket.
A korai fellendülést a 70-es években felváltotta az úgynevezett „MI-tél”, amikor is a mesterséges intelligenciával kapcsolatos kutatások megritkultak, az érdeklődés pedig megcsappant. Azt, hogy ezek a módszerek mégsem végezték úgy, mint sok más, szűk körben kutatott terület, a hardverek egyre gyorsuló fejlődésének és az ezzel együtt rohamosan növekvő számítási teljesítménynek köszönhetjük. A 2000-es évek közepéig kellett várni arra, hogy az MI mint kutatási terület népszerű legyen, és megérkezzenek az első igazán meggyőző eredmények. A grafikus processzorok (GPU-k) – amelyek több millió párhuzamos feldolgozóegységet tartalmaznak – elterjedése tette lehetővé, hogy hatalmas mennyiségű adat felhasználásával, rendkívül összetett modelleket lehessen tanítani, ezáltal eljutva az LLM-ekhez.
Az LLM-ek az MI családfáján
Ahogyan az ember is csupán egy apró hajtás az evolúció fáján, úgy az LLM-ek is csak egy messzi leágazást képviselnek az MI területén. Ráadásul a helyzetet tovább bonyolítja, hogy az egyes módszerek több különböző tulajdonság szerint csoportosíthatók: például aszerint, milyen feladatot látnak el, vagy hogy milyen alkalmazási területen teszik ezt. Más algoritmusokra van szükség akkor, ha embereket kell felismerni és megtalálni videófelvételeken, mint akkor, amikor az időjárás előrejelzése vagy új gyógyszer megfelelő vegyi összetevőinek megtalálása a cél.
Fontos különbségtételi szempont az is, hogy a modellek milyen módon lettek betanítva: előre összegyűjtött és megtisztított adatokon, vagy éppen éles helyzetben, közvetlenül a környezetükre reagálva tanulnak.
A legfontosabb elkülönítési szempont azonban a modell típusa, ami az algoritmus felépítését jelzi. Ez lehet akár egy egészen egyszerű módszer is, például megadott adatpontokra legjobban illeszkedő egyenes (ezt nevezzük lineáris regressziónak), míg a komplexitás másik végén az LLM-eket és a szöveges leírásból képeket generáló diffúziós modelleket találjuk.
Ahogy a biológiában a fajok, úgy az LLM-ek is besorolhatók egyre nagyobb, egymásba illeszkedő kategóriákba:
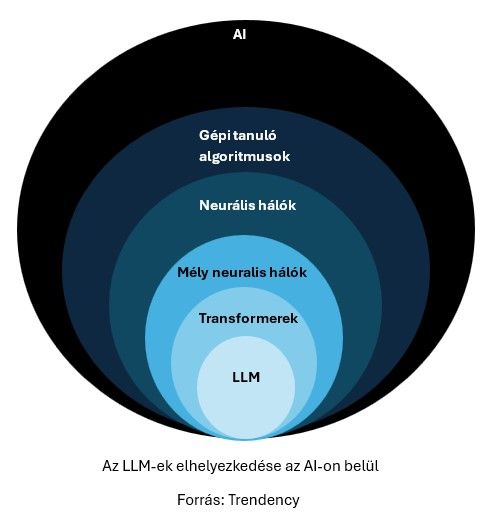
A neurális hálók alkotják az MI legelterjedtebb modellcsaládját. Ezek működése az emberi idegrendszerben található neuronokhoz hasonló – innen a nevük is. Kis feldolgozóegységek sokaságából épülnek fel, amelyek mind-mind saját paraméterekkel rendelkeznek, és ezekben tárolják a megtanult információt. A mély neurális hálók különlegessége, hogy sokrétegnyi ilyen feldolgozóegységből (neuronból) állnak, amelyeken keresztülhalad az információ a modell használata során, és az utolsó réteg szolgáltatja az eredményt – például egy számot vagy szót.
A neurális hálók legmodernebb és legelterjedtebb típusa a Transformer, amelyet 2017-ben mutattak be. Ez a modell az úgynevezett attention mechanizmusra épül, amely hosszú szövegekben is képes megtalálni a releváns információt. Ez a képesség tette a Transformert ideális alappá a nagy nyelvi modellek számára. Az összes mai LLM (ChatGPT, Claude, Gemini, Grok, DeepSeek… stb.) különféle Transformer-alapú architektúrákra épül, eltérő adatbázis-variánsokon tanítva.
Az LLM-ek tehát gépi tanulás útján készülő Transformer-modellek, amelyek nagyon nagy mennyiségű szöveges adat feldolgozásával tanulják meg, hogyan folytassanak egy megkezdett szövegrészt.
Amikor „beszélgetünk” velük, lényegében a tanítás során látott, hatalmas mennyiségű szöveghez hasonlót igyekeznek előállítani a válaszaikkal.
A ChatGPT-t és a többi olyan modellt, amellyel „beszélgetni” lehet, célzottan párbeszédeken tanították, hogy képesek legyenek ezt a fajta beszélgetésmódot imitálni. Az az igazság, hogy minden üzenetváltáskor figyelembe veszik a teljes korábbi beszélgetést, és a válaszokat ennek alapján generálják.
Az MI jövője
Mint az egyik legdinamikusabban fejlődő terület, az MI folyamatosan mozgásban van: hétről hétre publikálnak új cikkeket, tesznek elérhetővé új modelleket, és az LLM-eken kívül számos más területen is forradalmi változásokat ígérnek – például az egyre fejlettebb kép- és videógenerálás, az orvostudományban a diagnosztizálás vagy akár az önvezető autók fejlesztésében. Fontos azonban ezeket a módszereket a helyükön kezelni, és tisztában lenni a korlátaikkal.
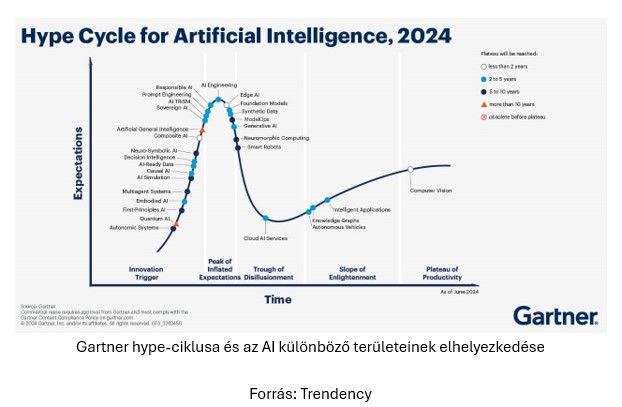
Ahogy minden technológiai újdonságot, úgy az MI fejlődését is gyakran kíséri túlzott lelkesedés. Az új vagy szimplán túlhájpolt módszerek kapcsán a területhez kevésbé értő szereplők és laikus kommentelők sokszor túlzó vagy félrevezető állításokat tesznek közzé. Ilyenkor könnyen elterjednek álhírek, csúsztatások, sőt, világraszóló ígéretek olyan modellekről, amelyek valójában még gyerekcipőben járnak. Ha ilyennel találkozunk, mindig jusson eszünkbe, hogy az MI nem varázslat. Ezek a modellek bonyolult algoritmusok mentén épülnek fel, és megfelelő használat mellett rengeteg problémára jelenthetnek megoldást. Azonban fontos, hogy minél inkább tisztában legyünk az adott MI-rendszer működésével, és minél szélesebb körű, hiteles forrásból származó rálátásunk legyen a területre.
A friss, felkapott technológiák egy idő után elfoglalják az őket megillető helyet az iparban használatos, jól bejáratott eszközök mellett, vagy zsákutcába futnak. Hogy ez mikor történik meg, és végül mely modellek bizonyulnak a legjobbnak, azt senki nem tudja megjósolni – de minél többet tudunk a témában, annál jobban fel tudjuk mérni az újdonságok valódi értékét és a használatukból eredő esetleges kockázatokat.








